Lý thuyết
Nhận dạng ký tự quang học (Optical Character Recognition – OCR) là kĩ thuật chuyển đổi hình ảnh chữ viết tay hoặc đánh máy thành các văn bản tài liệu. Công nghệ này hiện được phát triển thành nhiều ứng dụng hữu ích như dịch thuật theo thời gian thực, định danh khách hàng điện tử hay xử lý hóa đơn, chứng từ,…. Ngày nay, OCR có khả năng xử lí trên 200 ngôn ngữ và hứa hẹn sẽ tiếp tục mang lại những bước tiến vượt bậc nhờ Trí tuệ nhân tạo.
Có nhiều thư viện OCR, trong đó phổ biến nhất là Tesseract OCR: cung cấp một công cụ OCR – libtesseract và chương trình dòng lệnh – tesseract. So với phiên bản Tesseract 3 thì Tesseract 4 bổ sung một công cụ OCR dựa trên mạng thần kinh nhân tạo (LSTM), tập trung vào nhận dạng dòng và các mẫu ký tự. Tesseract hỗ trợ nhiều định dạng đầu ra như văn bản, hOCR (HTML), PDF, TSV, cũng như thử nghiệm đầu ra ALTO (XML).
Cài đặt thư viện:
-
Tải file cài đặt và chạy Tesseract-OCR installation file
-
Chọn ngôn ngữ
-
Chọn Next > :
-
Đọc cam kết rồi chọn I Agree
-
Chọn cài đặt cho 1 user hay toàn bộ user trong máy rồi chọn Next > :
-
Chọn thành phần cài đặt, nhớ chọn ngôn ngữ OCR
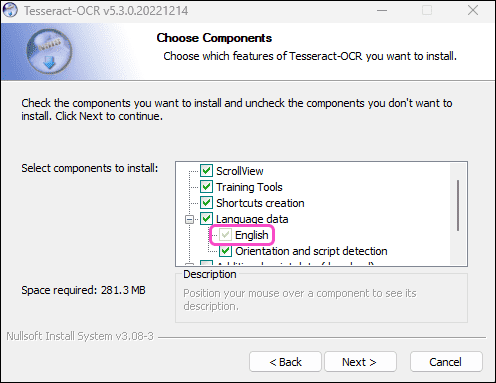
-
Chọn Next > :
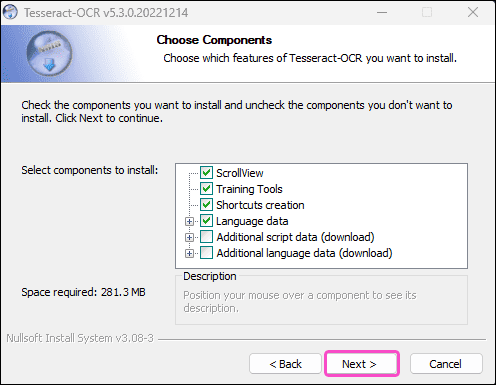
-
Chọn nơi cài Tesseract-OCR, hoặc dùng nơi cài mặc định
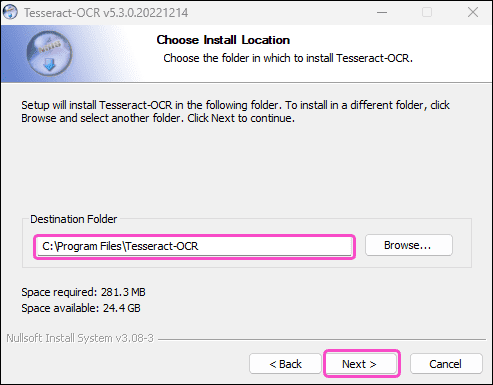
-
Chọn Install :
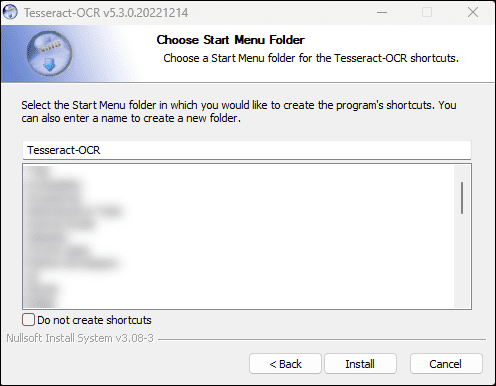
-
Sau khi cài đặt xong, chọn Next > :
-
Chọn Finish :
-
Cài đặt trong môi trường ảo:
conda install -c conda-forge pytesseract pillow
9.1. OCR ảnh